← Back to Blog
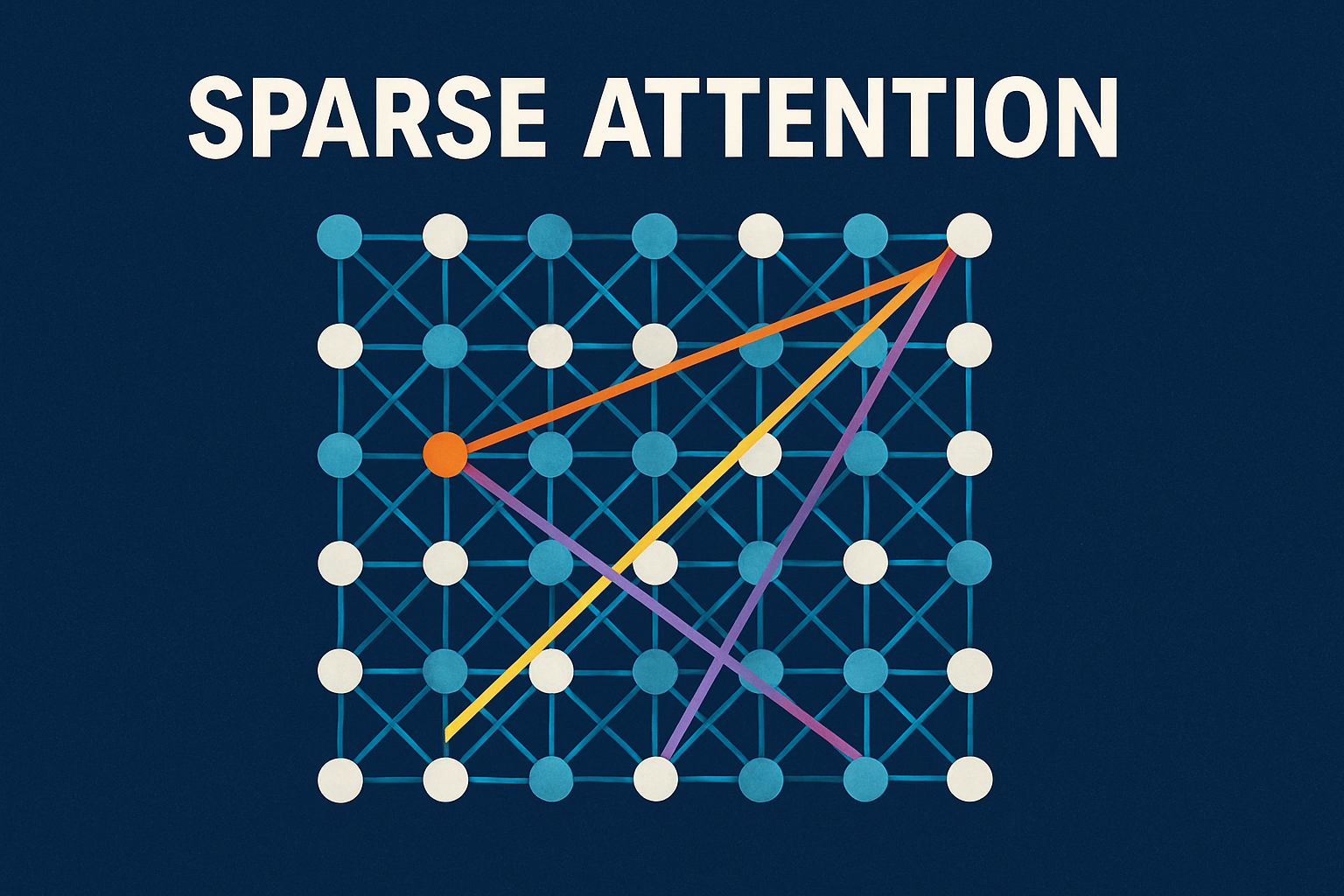
Sparse attention is a smarter version of normal attention used in transformer models. In regular (dense) attention, every token looks at every other token, which means a lot of unnecessary computation — especially when the text is very long. It’s like trying to listen to every single person in a huge crowd all talking at once. That wastes time and energy.
Instead, sparse attention says, “Let’s not listen to everyone. Let’s just focus on the important or nearby people.” It reduces the number of connections by attending only to selected tokens — maybe the closest ones, maybe key tokens like headings, or maybe some special pattern chosen by the model. So the model still gets important information but without doing heavy extra work.
Because of this, sparse attention uses less memory, runs faster, and can handle much longer inputs than dense attention. It keeps performance almost the same but makes the computation far lighter. This is why newer large language models with huge context windows often use sparse attention.
In short, sparse attention means pay attention where it matters, ignore the rest — smart work instead of hard work.